A data engineer is designing a Lakeflow Declarative Pipeline to process streaming order data. The pipeline uses Auto Loader to ingest data and must enforce data quality by ensuring customer_id and amount are greater than zero. Invalid records should be dropped.
Which Lakeflow Declarative Pipelines configurations implement this requirement using Python?
A data engineer is configuring a Lakeflow Declarative Pipeline to process CDC (Change Data Capture) data from a source. The source events sometimes arrive out of order, and multiple updates may occur with the same update_timestamp but with different update_sequence_id .
What should the data engineer do to ensure events are sequenced correctly?
A table is registered with the following code:
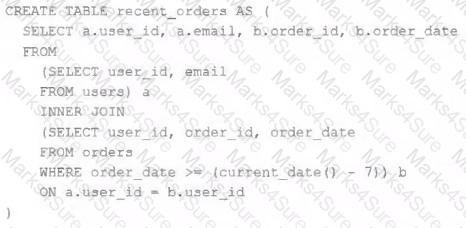
Both users and orders are Delta Lake tables. Which statement describes the results of querying recent_orders ?
The data engineer team has been tasked with configured connections to an external database that does not have a supported native connector with Databricks. The external database already has data security configured by group membership. These groups map directly to user group already created in Databricks that represent various teams within the company.
A new login credential has been created for each group in the external database. The Databricks Utilities Secrets module will be used to make these credentials available to Databricks users.
Assuming that all the credentials are configured correctly on the external database and group membership is properly configured on Databricks, which statement describes how teams can be granted the minimum necessary access to using these credentials?
A data engineer is performing a join operating to combine values from a static userlookup table with a streaming DataFrame streamingDF.
Which code block attempts to perform an invalid stream-static join?
To reduce storage and compute costs, the data engineering team has been tasked with curating a series of aggregate tables leveraged by business intelligence dashboards, customer-facing applications, production machine learning models, and ad hoc analytical queries.
The data engineering team has been made aware of new requirements from a customer-facing application, which is the only downstream workload they manage entirely. As a result, an aggregate table used by numerous teams across the organization will need to have a number of fields renamed, and additional fields will also be added.
Which of the solutions addresses the situation while minimally interrupting other teams in the organization without increasing the number of tables that need to be managed?
Which Python variable contains a list of directories to be searched when trying to locate required modules?
A junior data engineer seeks to leverage Delta Lake ' s Change Data Feed functionality to create a Type 1 table representing all of the values that have ever been valid for all rows in a bronze table created with the property delta.enableChangeDataFeed = true . They plan to execute the following code as a daily job:

Which statement describes the execution and results of running the above query multiple times?
A data engineer is tasked with ensuring that a Delta table in Databricks continuously retains deleted files for 15 days (instead of the default 7 days), in order to permanently comply with the organization’s data retention policy.
Which code snippet correctly sets this retention period for deleted files?
A data architect has heard about lake ' s built-in versioning and time travel capabilities. For auditing purposes they have a requirement to maintain a full of all valid street addresses as they appear in the customers table.
The architect is interested in implementing a Type 1 table, overwriting existing records with new values and relying on Delta Lake time travel to support long-term auditing. A data engineer on the project feels that a Type 2 table will provide better performance and scalability.
Which piece of information is critical to this decision?
A Databricks SQL dashboard has been configured to monitor the total number of records present in a collection of Delta Lake tables using the following query pattern:
SELECT COUNT (*) FROM table -
Which of the following describes how results are generated each time the dashboard is updated?
The Databricks CLI is use to trigger a run of an existing job by passing the job_id parameter. The response that the job run request has been submitted successfully includes a filed run_id.
Which statement describes what the number alongside this field represents?
Which of the following technologies can be used to identify key areas of text when parsing Spark Driver log4j output?
A data engineer is tasked with building a nightly batch ETL pipeline that processes very large volumes of raw JSON logs from a data lake into Delta tables for reporting. The data arrives in bulk once per day, and the pipeline takes several hours to complete. Cost efficiency is important, but performance and reliability of completing the pipeline are the highest priorities.
Which type of Databricks cluster should the data engineer configure?
The business reporting tem requires that data for their dashboards be updated every hour. The total processing time for the pipeline that extracts transforms and load the data for their pipeline runs in 10 minutes.
Assuming normal operating conditions, which configuration will meet their service-level agreement requirements with the lowest cost?
In order to facilitate near real-time workloads, a data engineer is creating a helper function to leverage the schema detection and evolution functionality of Databricks Auto Loader. The desired function will automatically detect the schema of the source directly, incrementally process JSON files as they arrive in a source directory, and automatically evolve the schema of the table when new fields are detected.
The function is displayed below with a blank:

Which response correctly fills in the blank to meet the specified requirements?

The data architect has mandated that all tables in the Lakehouse should be configured as external (also known as " unmanaged " ) Delta Lake tables.
Which approach will ensure that this requirement is met?
A company wants to implement Lakehouse Federation across multiple data sources but is concerned about data consistency and ensuring that all teams access the same authoritative version of their data.
Which statement is applicable for Lakehouse Federations to maintain data consistency?
Given the following PySpark code snippet in a Databricks notebook:
filtered_df = spark.read.format( " delta " ).load( " /mnt/data/large_table " ) \
.filter( " event_date > ' 2024-01-01 ' " )
filtered_df.count()
The data engineer notices from the Query Profiler that the scan operator for filtered_df is reading almost all files, despite the filter being applied.
What is the probable reason for poor data skipping?
A senior data engineer is planning large-scale data workflows. The task is to identify the considerations that form a foundation for creating scalable data models for managing large datasets. The team has listed Delta Lake capabilities and wants to determine which feature should not be considered as a core factor.
Which key feature can be ignored while evaluating Delta Lake?
A data engineer wants to reflector the following DLT code, which includes multiple definition with very similar code:

In an attempt to programmatically create these tables using a parameterized table definition, the data engineer writes the following code.

The pipeline runs an update with this refactored code, but generates a different DAG showing incorrect configuration values for tables.
How can the data engineer fix this?
What is the first of a Databricks Python notebook when viewed in a text editor?
A member of the data engineering team has submitted a short notebook that they wish to schedule as part of a larger data pipeline. Assume that the commands provided below produce the logically correct results when run as presented.

Which command should be removed from the notebook before scheduling it as a job?
A data engineer, while designing a Pandas UDF to process financial time-series data with complex calculations that require maintaining state across rows within each stock symbol group, must ensure the function is efficient and scalable.
Which approach will solve the problem with minimum overhead while preserving data integrity?
A Structured Streaming job deployed to production has been resulting in higher than expected cloud storage costs. At present, during normal execution, each micro-batch of data is processed in less than 3 seconds; at least 12 times per minute, a micro-batch is processed that contains 0 records. The streaming write was configured using the default trigger settings. The production job is currently scheduled alongside many other Databricks jobs in a workspace with instance pools provisioned to reduce start-up time for jobs with batch execution. Holding all other variables constant and assuming records need to be processed in less than 10 minutes, which adjustment will meet the requirement?
A junior member of the data engineering team is exploring the language interoperability of Databricks notebooks. The intended outcome of the below code is to register a view of all sales that occurred in countries on the continent of Africa that appear in the geo_lookup table.
Before executing the code, running SHOW TABLES on the current database indicates the database contains only two tables: geo_lookup and sales .

Which statement correctly describes the outcome of executing these command cells in order in an interactive notebook?
Given the following error traceback (from display(df.select(3* " heartrate " ))) which shows AnalysisException: cannot resolve ' heartrateheartrateheartrate ' , which statement describes the error being raised?
A junior data engineer has been asked to develop a streaming data pipeline with a grouped aggregation using DataFrame df. The pipeline needs to calculate the average humidity and average temperature for each non-overlapping five-minute interval. Events are recorded once per minute per device.
df has the following schema: device_id INT, event_time TIMESTAMP, temp FLOAT, humidity FLOAT
Code block:
df.withWatermark( " event_time " , " 10 minutes " )
.groupBy(
________,
" device_id "
)
.agg(
avg( " temp " ).alias( " avg_temp " ),
avg( " humidity " ).alias( " avg_humidity " )
)
.writeStream
.format( " delta " )
.saveAsTable( " sensor_avg " )
Which line of code correctly fills in the blank within the code block to complete this task?
A data engineer is designing a Lakeflow Spark Declarative Pipeline to process streaming order data. The pipeline uses Auto Loader to ingest data and must enforce data quality by ensuring customer_id is not null and amount is greater than zero. Invalid records should be dropped. Which Lakeflow Spark Declarative Pipelines configuration implements this requirement using Python?
A junior data engineer has been asked to develop a streaming data pipeline with a grouped aggregation using DataFrame df . The pipeline needs to calculate the average humidity and average temperature for each non-overlapping five-minute interval. Events are recorded once per minute per device.
Streaming DataFrame df has the following schema:
" device_id INT, event_time TIMESTAMP, temp FLOAT, humidity FLOAT "
Code block:

Choose the response that correctly fills in the blank within the code block to complete this task.
A data engineer is using Auto Loader to read incoming JSON data as it arrives. They have configured Auto Loader to quarantine invalid JSON records but notice that over time, some records are being quarantined even though they are well-formed JSON .
The code snippet is:
df = (spark.readStream
.format( " cloudFiles " )
.option( " cloudFiles.format " , " json " )
.option( " badRecordsPath " , " /tmp/somewhere/badRecordsPath " )
.schema( " a int, b int " )
.load( " /Volumes/catalog/schema/raw_data/ " ))
What is the cause of the missing data?
A junior developer complains that the code in their notebook isn ' t producing the correct results in the development environment. A shared screenshot reveals that while they ' re using a notebook versioned with Databricks Repos, they ' re using a personal branch that contains old logic. The desired branch named dev-2.3.9 is not available from the branch selection dropdown.
Which approach will allow this developer to review the current logic for this notebook?
A junior data engineer has been asked to develop a streaming data pipeline with a grouped aggregation using DataFrame df. The pipeline needs to calculate the average humidity and average temperature for each non-overlapping five-minute interval. Incremental state information should be maintained for 10 minutes for late-arriving data.
Streaming DataFrame df has the following schema:
" device_id INT, event_time TIMESTAMP, temp FLOAT, humidity FLOAT "
Code block:

Choose the response that correctly fills in the blank within the code block to complete this task.
A small company based in the United States has recently contracted a consulting firm in India to implement several new data engineering pipelines to power artificial intelligence applications. All the company ' s data is stored in regional cloud storage in the United States.
The workspace administrator at the company is uncertain about where the Databricks workspace used by the contractors should be deployed.
Assuming that all data governance considerations are accounted for, which statement accurately informs this decision?
A departing platform owner currently holds ownership of multiple catalogs and controls storage credentials and external locations. A data engineer has been asked to ensure continuity: transfer catalog ownership to the platform team group, delegate ongoing privilege management, and retain the ability to receive and share data via Delta Sharing.
Which role must be in place to perform these actions across the metastore?
A data engineer is implementing Unity Catalog governance for a multi-team environment. Data scientists need interactive clusters for basic data exploration tasks, while automated ETL jobs require dedicated processing.
How should the data engineer configure cluster isolation policies to enforce least privilege and ensure Unity Catalog compliance?
While reviewing a query ' s execution in the Databricks Query Profiler, a data engineer observes that the Top Operators panel shows a Sort operator with high Time Spent and Memory Peak metrics. The Spark UI also reports frequent data spilling .
How should the data engineer address this issue?
A data engineer is designing an append-only pipeline that needs to handle both batch and streaming data in Delta Lake. The team wants to ensure that the streaming component can efficiently track which data has already been processed.
Which configuration should be set to enable this?
A data engineer needs to install the PyYAML Python package within an air-gapped Databricks environment . The workspace has no direct internet access to PyPI. The engineer has downloaded the .whl file locally and wants it available automatically on all new clusters.
Which approach should the data engineer use?
Which statement regarding stream-static joins and static Delta tables is correct?
A data engineer has configured their Databricks Asset Bundle with multiple targets in databricks.yml and deployed it to the production workspace. Now, to validate the deployment, they need to invoke a job named my_project_job specifically within the prod target context. Assuming the job is already deployed, they need to trigger its execution while ensuring the target-specific configuration is respected.
Which command will trigger the job execution?
Given the following error traceback:
AnalysisException: cannot resolve ' heartrateheartrateheartrate ' given input columns:
[spark_catalog.database.table.device_id, spark_catalog.database.table.heartrate,
spark_catalog.database.table.mrn, spark_catalog.database.table.time]
The code snippet was:
display(df.select(3* " heartrate " ))
Which statement describes the error being raised?
A data engineer deploys a multi-task Databricks job that orchestrates three notebooks. One task intermittently fails with Exit Code 1 but succeeds on retry. The engineer needs to collect detailed logs for the failing attempts, including stdout/stderr and cluster lifecycle context, and share them with the platform team.
What steps the data engineer needs to follow using built-in tools?
A data engineering team is migrating off its legacy Hadoop platform. As part of the process, they are evaluating storage formats for performance comparison. The legacy platform uses ORC and RCFile formats. After converting a subset of data to Delta Lake , they noticed significantly better query performance. Upon investigation, they discovered that queries reading from Delta tables leveraged a Shuffle Hash Join , whereas queries on legacy formats used Sort Merge Joins . The queries reading Delta Lake data also scanned less data.
Which reason could be attributed to the difference in query performance?
A Databricks job has been configured with 3 tasks, each of which is a Databricks notebook. Task A does not depend on other tasks. Tasks B and C run in parallel, with each having a serial dependency on Task A.
If task A fails during a scheduled run, which statement describes the results of this run?
A data architect is designing a Databricks solution to efficiently process data for different business requirements.
In which scenario should a data engineer use a materialized view compared to a streaming table ?
A data pipeline uses Structured Streaming to ingest data from kafka to Delta Lake. Data is being stored in a bronze table, and includes the Kafka_generated timesamp, key, and value. Three months after the pipeline is deployed the data engineering team has noticed some latency issued during certain times of the day.
A senior data engineer updates the Delta Table ' s schema and ingestion logic to include the current timestamp (as recoded by Apache Spark) as well the Kafka topic and partition. The team plans to use the additional metadata fields to diagnose the transient processing delays:
Which limitation will the team face while diagnosing this problem?
A data engineer, while designing a Pandas UDF to process financial time-series data with complex calculations that require maintaining state across rows within each stock symbol group, must ensure the function is efficient and scalable. Which approach will solve the problem with minimum overhead while preserving data integrity?
A task orchestrator has been configured to run two hourly tasks. First, an outside system writes Parquet data to a directory mounted at /mnt/raw_orders/. After this data is written, a Databricks job containing the following code is executed:
(spark.readStream
.format( " parquet " )
.load( " /mnt/raw_orders/ " )
.withWatermark( " time " , " 2 hours " )
.dropDuplicates([ " customer_id " , " order_id " ])
.writeStream
.trigger(once=True)
.table( " orders " )
)
Assume that the fields customer_id and order_id serve as a composite key to uniquely identify each order, and that the time field indicates when the record was queued in the source system. If the upstream system is known to occasionally enqueue duplicate entries for a single order hours apart, which statement is correct?
A junior data engineer is migrating a workload from a relational database system to the Databricks Lakehouse. The source system uses a star schema, leveraging foreign key constrains and multi-table inserts to validate records on write.
Which consideration will impact the decisions made by the engineer while migrating this workload?
The view updates represents an incremental batch of all newly ingested data to be inserted or updated in the customers table.
The following logic is used to process these records.

Which statement describes this implementation?
A Delta table of weather records is partitioned by date and has the below schema:
date DATE, device_id INT, temp FLOAT, latitude FLOAT, longitude FLOAT
To find all the records from within the Arctic Circle, you execute a query with the below filter:
latitude > 66.3
Which statement describes how the Delta engine identifies which files to load?
A junior data engineer has configured a workload that posts the following JSON to the Databricks REST API endpoint 2.0/jobs/create .

Assuming that all configurations and referenced resources are available, which statement describes the result of executing this workload three times?
A data team ' s Structured Streaming job is configured to calculate running aggregates for item sales to update a downstream marketing dashboard. The marketing team has introduced a new field to track the number of times this promotion code is used for each item. A junior data engineer suggests updating the existing query as follows: Note that proposed changes are in bold.

Which step must also be completed to put the proposed query into production?


TESTED 05 May 2026