Free Practice Questions for the Microsoft Certified: Fabric Analytics Engineer Associate DP-600 Exam (2026 Updated)
At Marks4sure, we are dedicated to providing IT professionals with the most accurate and reliable preparation materials for the Microsoft DP-600 exam. To support your certification journey, we have made a selection of our premium 2026 Microsoft Certified: Fabric Analytics Engineer Associate practice questions and answers available completely free. You can take this practice test as many times as you need. Every question includes a detailed, expertly verified explanation to ensure you fully grasp the core security concepts before test day.
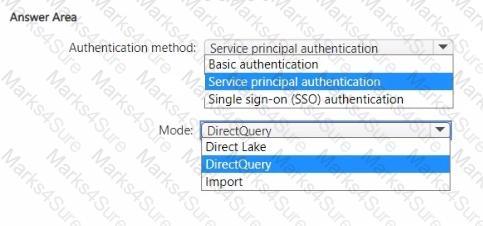
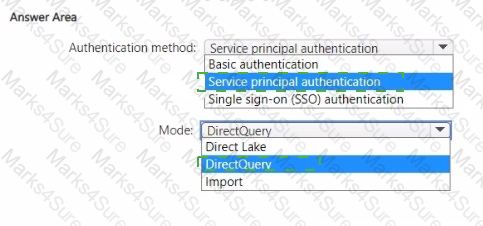
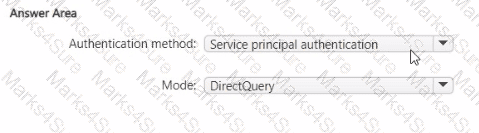
You need to design a semantic model for the customer satisfaction report.
Which data source authentication method and mode should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
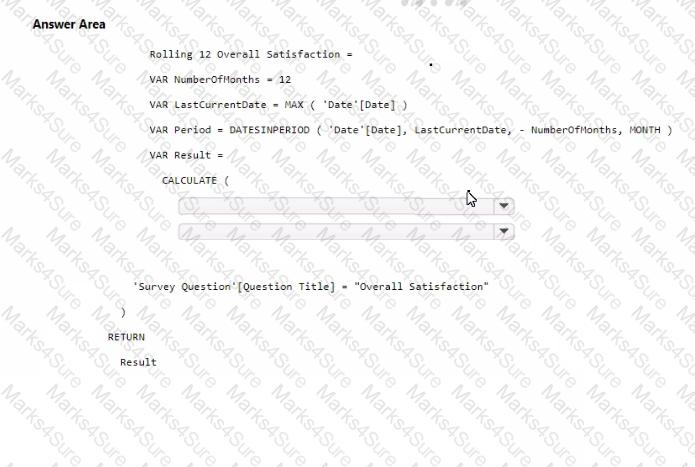
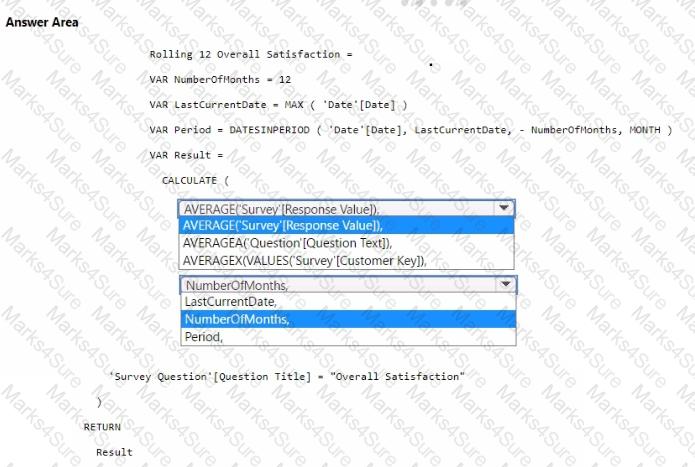
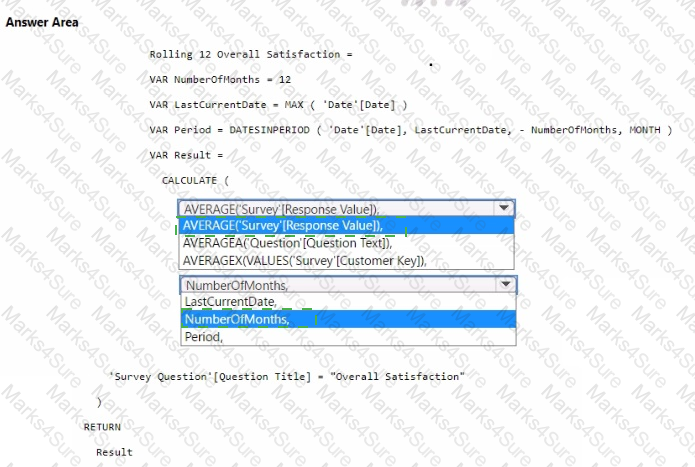
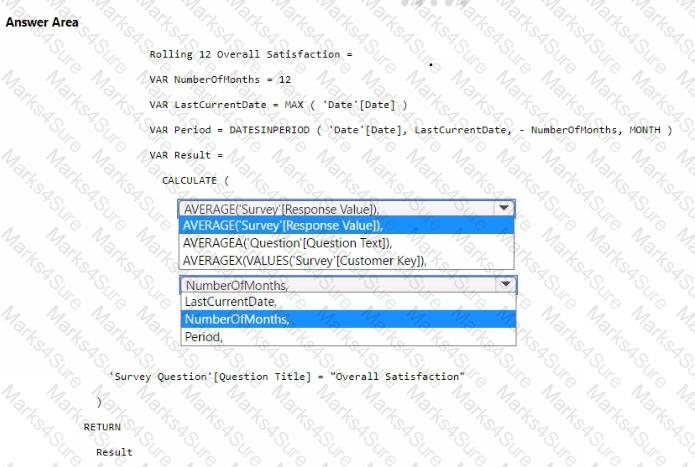
You need to create a DAX measure to calculate the average overall satisfaction score.
How should you complete the DAX code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You need to ensure the data loading activities in the AnalyticsPOC workspace are executed in the appropriate sequence. The solution must meet the technical requirements.
What should you do?
What should you use to implement calculation groups for the Research division semantic models?
Which syntax should you use in a notebook to access the Research division data for Productlinel?
A)
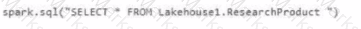
B)
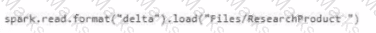
C)
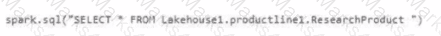
D)

You need to recommend which type of fabric capacity SKU meets the data analytics requirements for the Research division. What should you recommend?
You need to refresh the Orders table of the Online Sales department. The solution must meet the semantic model requirements. What should you include in the solution?
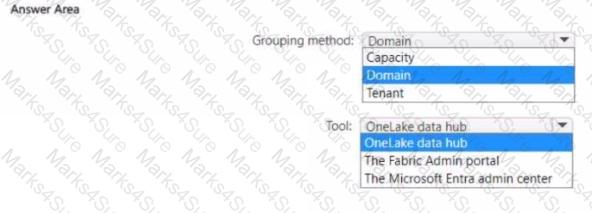
You need to recommend a solution to group the Research division workspaces.
What should you include in the recommendation? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


Which workspace rote assignments should you recommend for ResearchReviewersGroupl and ResearchReviewersGroupZ? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.



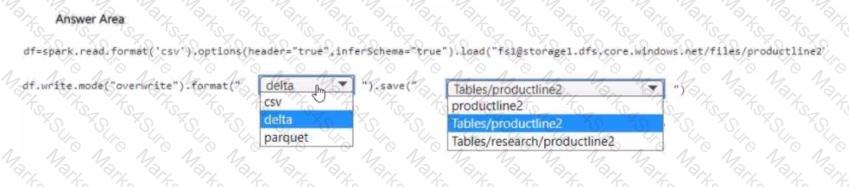
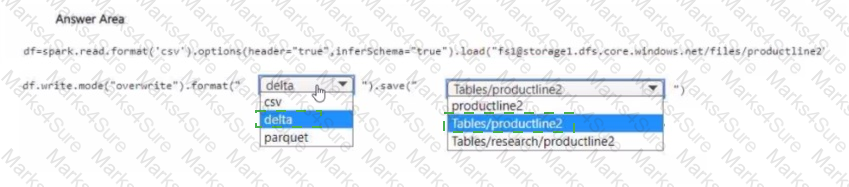
You need to migrate the Research division data for Productline2. The solution must meet the data preparation requirements. How should you complete the code? To answer, select the appropriate options in the answer area
NOTE: Each correct selection is worth one point.

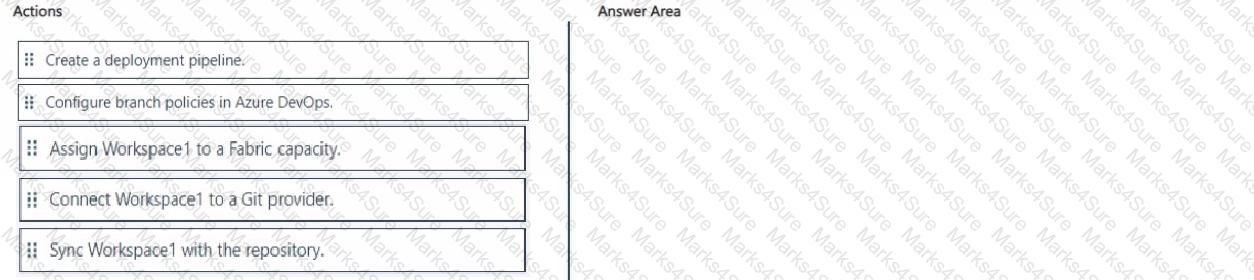
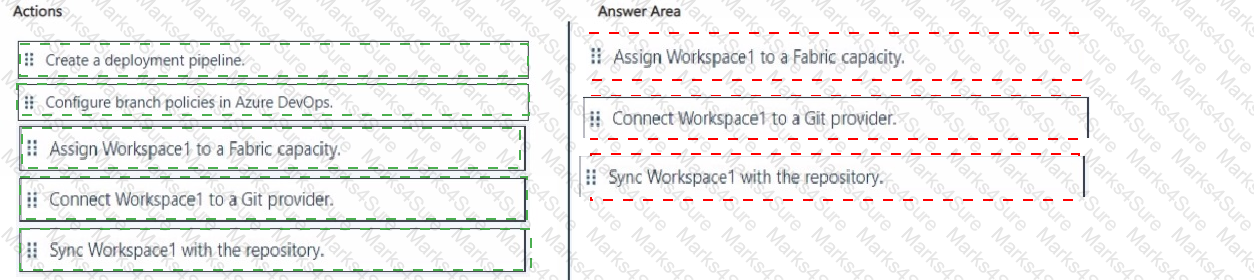
You need to ensure that Contoso can use version control to meet the data analytics requirements and the general requirements. What should you do?
What should you recommend using to ingest the customer data into the data store in the AnatyticsPOC workspace?
You have a Fabric tenant that contains a workspace named Workspace! Workspace1 uses the Pro license mode and contains a semantic model named Model1.
You have an Azure DevOps organization.
You need to enable version control for Workspace1. The solution must ensure that Model 1 is added to the repository.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

You have a Fabric tenant that contains a lakehouse named Lakehouse1
Readings from 100 loT devices are appended to a Delta table in Lakehouse1. Each set of readings is approximately 25 KB. Approximately 10 GB of data is received daily.
All the table and SparkSession settings are set to the default.
You discover that queries are slow to execute. In addition, the lakehouse storage contains data and log files that are no longer used.
You need to remove the files that are no longer used and combine small files into larger files with a target size of 1 GB per file.
What should you do? To answer, drag the appropriate actions to the correct requirements. Each action may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.


You to need assign permissions for the data store in the AnalyticsPOC workspace. The solution must meet the security requirements.
Which additional permissions should you assign when you share the data store? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.


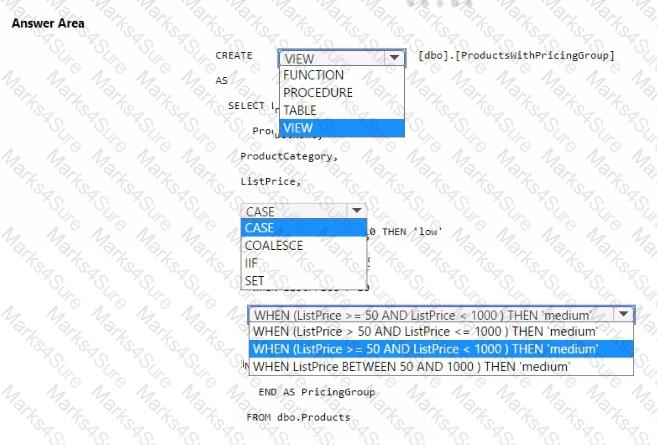
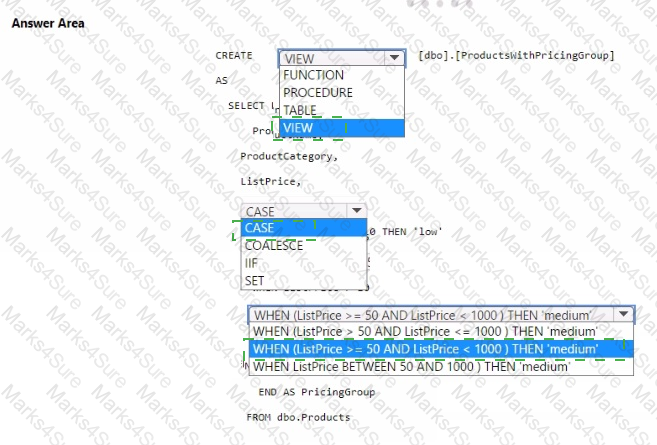
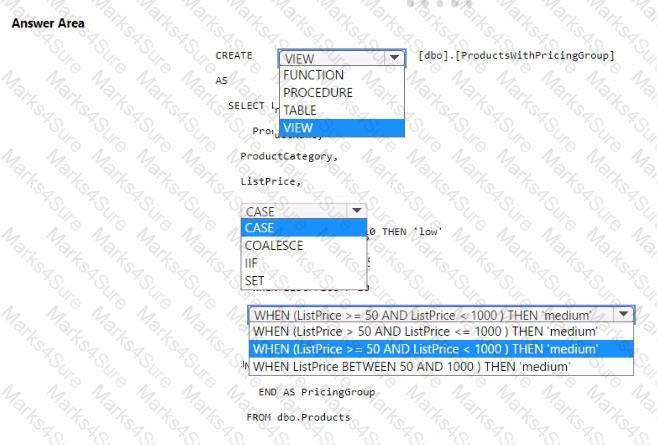
You need to resolve the issue with the pricing group classification.
How should you complete the T-SQL statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
PDF + Testing Engine

Testing Engine
PDF (Q&A)
